Policy Liberalism
policy_liberalism.RmdThis vignette demonstrates estimation of latent policy liberalism from individuals’ responses to five survey items, using the Bayesian group-level IRT model implemented in dgirt().
Prepare input data
shape() prepares input data for use with the modeling functions dgirt() and dgmrp(). Here we use the included opinion dataset.
dgirt_in_liberalism <- shape(opinion, item_names = c("abortion",
"affirmative_action","stemcell_research" , "gaymarriage_amendment",
"partialbirth_abortion") , time_name = "year", geo_name = "state",
group_names = "race3", geo_filter = c("CA", "GA", "LA", "MA"))
#> Applying restrictions, pass 1...
#> Dropped 5 rows for missingness in covariates
#> Dropped 8 rows for lacking item responses
#> Applying restrictions, pass 2...
#> No changesIn this call to shape() we specified:
- the survey item response variables as
item_names; - which variable represents time (
year), since dgo models are dynamic; - the variables representing respondent characteristics (
stateandrace3), because dgo models are group-level.
Notice that we named only one of these variables defining respondent groups using the group_names argument. The geo_name argument always takes the variable giving respondents’ local geographic area; it will be modeled differently.
Using the argument geo_filter, we subset the input data to the given values of the geo_name variable. And with the id_vars argument, we named an identfier that we’d like to keep in the processed data. (Other unused variables will be dropped.)
Important: the dgirt() model assumes consistent coding of the polarity of item responses for identification. This is already true for the opinion data. Typically it requires manual recoding.
Inspect the result
summary() gives a high-level description of the result.
summary(dgirt_in_liberalism)
#> Items:
#> [1] "abortion" "affirmative_action" "gaymarriage_amendment"
#> [4] "partialbirth_abortion" "stemcell_research"
#> Respondents:
#> 23,632 in `item_data`
#> Grouping variables:
#> [1] "year" "state" "race3"
#> Time periods:
#> [1] 2006 2007 2008 2009 2010
#> Local geographic areas:
#> [1] "CA" "GA" "LA" "MA"
#> Hierarchical parameters:
#> [1] "GA" "LA" "MA" "race3other" "race3white"
#> Modifiers of hierarchical parameters:
#> NULL
#> Constants:
#> Q T P N G H D
#> 5 5 5 300 12 1 1get_n() and get_item_n() give response counts.
get_n(dgirt_in_liberalism, by = "state")
#> state n
#> 1: CA 14655
#> 2: GA 4667
#> 3: LA 1693
#> 4: MA 2617
get_item_n(dgirt_in_liberalism, by = "year")
#> year abortion affirmative_action stemcell_research
#> 1: 2006 5275 4750 2483
#> 2: 2007 1690 1557 1705
#> 3: 2008 4697 4704 4002
#> 4: 2009 2141 2147 0
#> 5: 2010 9204 9241 9146
#> gaymarriage_amendment partialbirth_abortion
#> 1: 2642 5064
#> 2: 1163 1684
#> 3: 4265 0
#> 4: 0 0
#> 5: 9226 0Fit a model
dgirt() estimates a latent variable based on responses to multiple survey questions. Here, we’ll use it to estimate latent policy liberalism over time, for the groups defined by state and race3. (Specifically, by their Cartesian product.)
Under the hood, dgirt() uses RStan for MCMC sampling, and arguments can be passed to RStan’s stan() via the ... argument of dgirt(). This is almost always desirable. Here, we specify the number of sampler iterations, chains, and cores.
The model results are held in a dgirt_fit object. Methods from RStan like extract() are available if needed because dgirt_fit is a subclass of stanfit. But dgo provides its own methods for typical post-estimation tasks.
Work with results
For a high-level summary of the result, use summary().
summary(dgirt_out_liberalism)
#> dgirt samples from 4 chains of 3000 iterations, 1500 warmup, thinned every 1
#> Drawn Mon Jul 16 21:17:33 2018
#> Package version 0.3.0
#> Model version 2017_01_04
#> 137 parameters; 60 theta_bars (year state race3)
#> 5 periods 2006 to 2010
#>
#> n_eff
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 3.311 6.104 9.190 133.762 36.420 2936.615
#>
#> Rhat
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1.002 1.054 1.116 1.133 1.194 1.520
#>
#> Elapsed time
#> chain warmup sample total
#> 1: 1 1M 48S 2M 29S 3M 77S
#> 2: 2 1M 56S 1M 15S 2M 71S
#> 3: 3 1M 53S 1S 1M 54S
#> 4: 4 1M 43S 1M 15S 2M 58STo apply scalar functions to posterior samples, use summarize(). The default output gives summary statistics for the model’s theta_bar parameters, which represent group means. These are indexed by time (year) and group, where groups are again defined by local geographic area (state) and any other respondent characteristics (race3).
head(summarize(dgirt_out_liberalism))
#> param state race3 year mean sd median q_025
#> 1: theta_bar CA black 2006 0.5449494 0.06939353 0.5489666 0.40415878
#> 2: theta_bar CA black 2007 0.6284050 0.09138017 0.6296205 0.46130379
#> 3: theta_bar CA black 2008 0.6081491 0.09182449 0.6221932 0.44715184
#> 4: theta_bar CA black 2009 0.5370828 0.07860631 0.5434493 0.39746663
#> 5: theta_bar CA black 2010 0.5127970 0.05612665 0.5177353 0.40241598
#> 6: theta_bar CA other 2006 0.1592489 0.05518974 0.1776783 0.02296132
#> q_975
#> 1: 0.6464371
#> 2: 0.7918857
#> 3: 0.8181405
#> 4: 0.7001926
#> 5: 0.6201621
#> 6: 0.2520605Alternatively, summarize() can apply arbitrary functions to posterior samples for whatever parameter is given by its pars argument.
summarize(dgirt_out_liberalism, pars = "xi", funs = "var")
#> param year var
#> 1: xi 2006 0.013140501
#> 2: xi 2007 0.009929009
#> 3: xi 2008 0.009743135
#> 4: xi 2009 0.006459165
#> 5: xi 2010 0.005759095To access posterior samples in tabular form use as.data.frame(). By default, this method returns post-warmup samples for the theta_bar parameters, but like other methods takes a pars argument.
head(as.data.frame(dgirt_out_liberalism))
#> param state race3 year iteration value
#> 1: theta_bar CA black 2006 1 0.5865184
#> 2: theta_bar CA black 2006 2 0.5516825
#> 3: theta_bar CA black 2006 3 0.5435844
#> 4: theta_bar CA black 2006 4 0.5717553
#> 5: theta_bar CA black 2006 5 0.4957044
#> 6: theta_bar CA black 2006 6 0.6094865To poststratify the results use poststratify(). Here, we use the group population proportions bundled as annual_state_race_targets to reweight and aggregate estimates to strata defined by state-years.
poststratify(dgirt_out_liberalism, annual_state_race_targets, strata_names =
c("state", "year"), aggregated_names = "race3")
#> state year iteration value
#> 1: CA 2006 1 0.16156947
#> 2: CA 2006 2 0.15329564
#> 3: CA 2006 3 0.19448980
#> 4: CA 2006 4 0.16727909
#> 5: CA 2006 5 0.14031044
#> ---
#> 119996: MA 2010 5996 0.12974189
#> 119997: MA 2010 5997 0.14531223
#> 119998: MA 2010 5998 0.07566858
#> 119999: MA 2010 5999 0.07904357
#> 120000: MA 2010 6000 0.06926404To plot the results use dgirt_plot(). This method plots summaries of posterior samples by time period. By default, it shows a 95% credible interval around posterior medians for the theta_bar parameters, for each local geographic area. Here we omit the CIs.
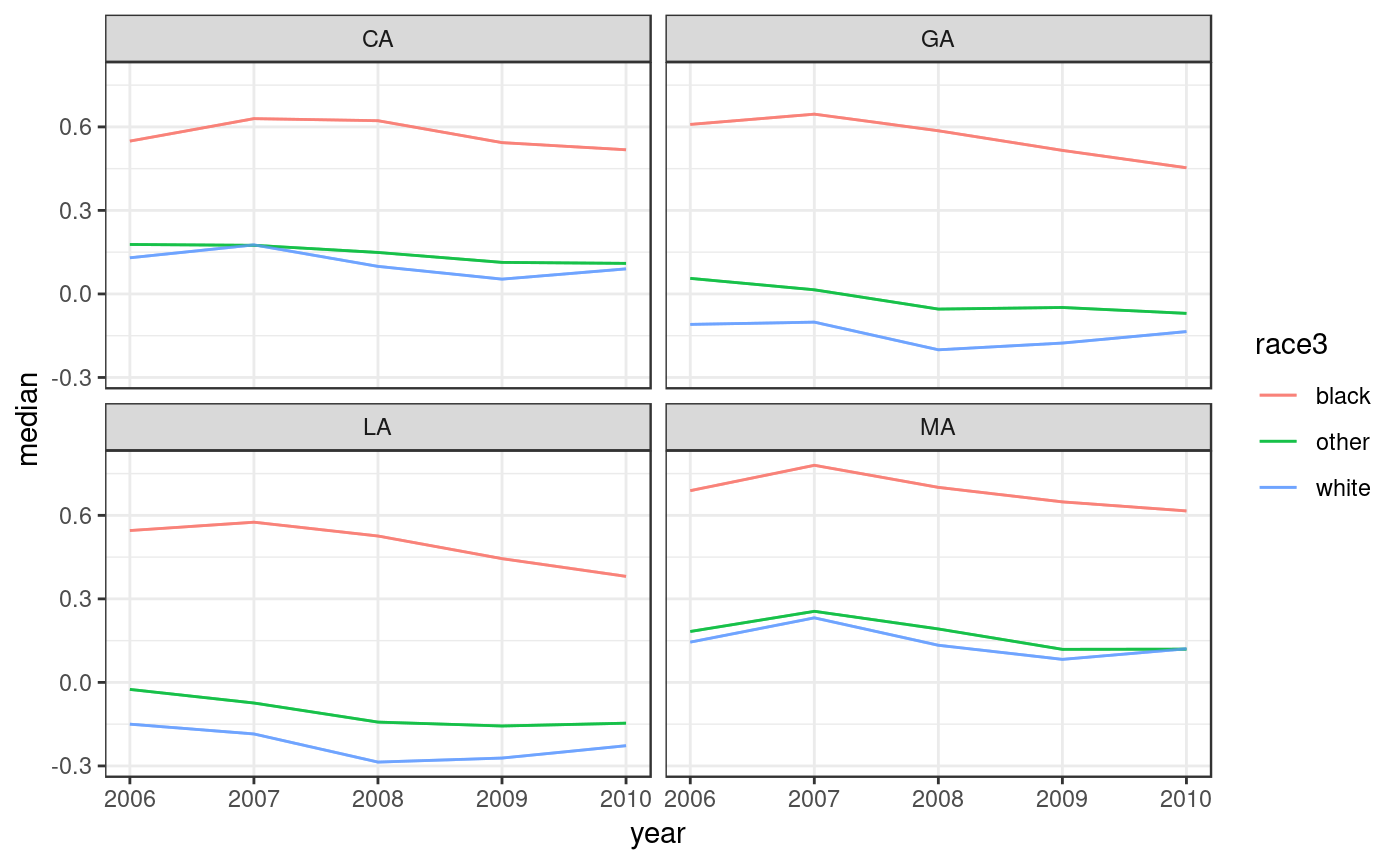
dgirt_plot() can also plot the data.frame output from poststratify(), given arguments that identify the relevant variables. Below, we aggregate over the demographic grouping variable race3, resulting in a data.frame of estimates by state-year.
ps <- poststratify(dgirt_out_liberalism, annual_state_race_targets, strata_names
= c("state", "year"), aggregated_names = "race3")
head(ps)
#> state year iteration value
#> 1: CA 2006 1 0.1615695
#> 2: CA 2006 2 0.1532956
#> 3: CA 2006 3 0.1944898
#> 4: CA 2006 4 0.1672791
#> 5: CA 2006 5 0.1403104
#> 6: CA 2006 6 0.1893262
dgirt_plot(ps, group_names = NULL, time_name = "year", geo_name = "state")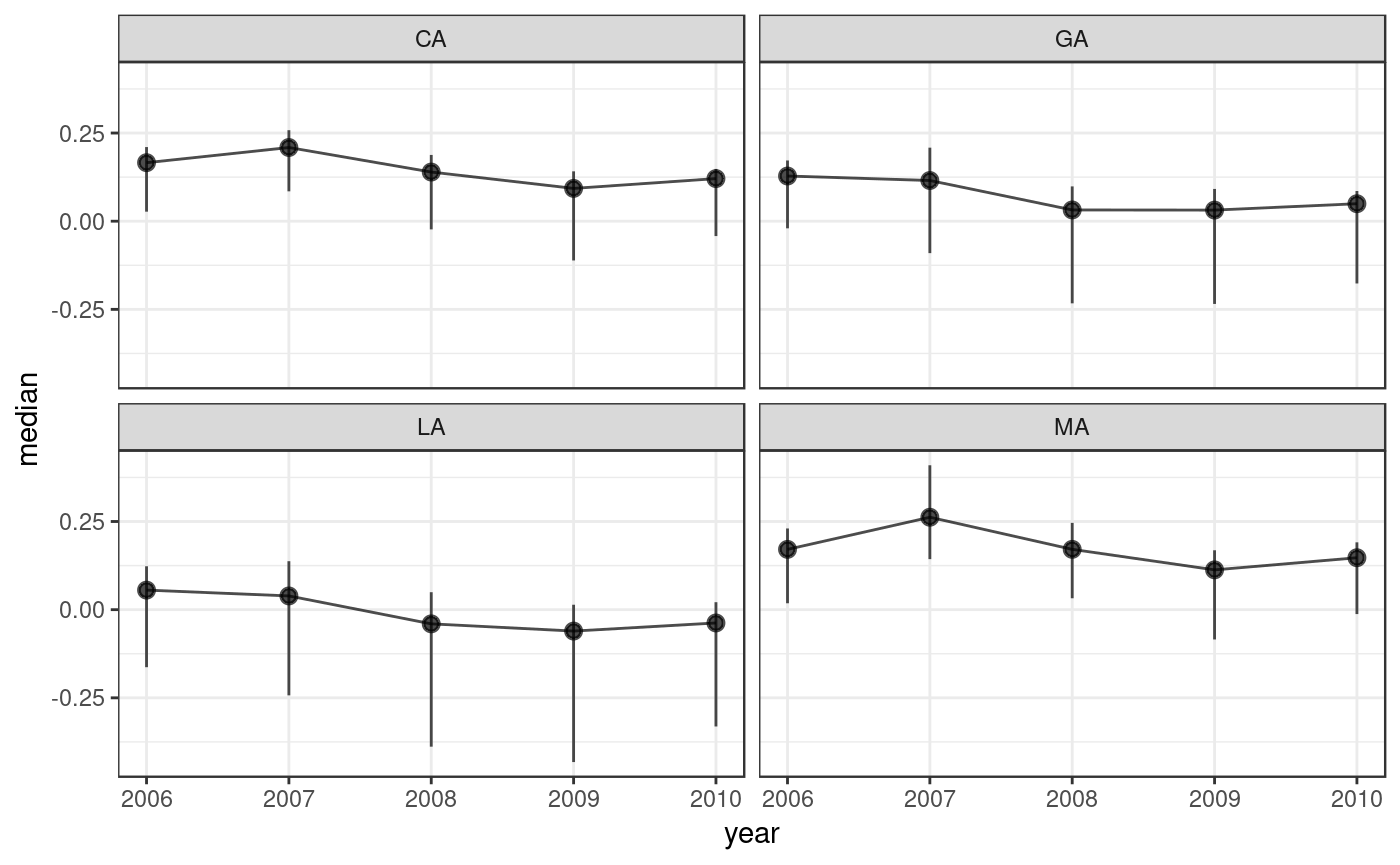
In the call to dgirt_plot(), we passed the names of the state and year variables. The group_names argument was then NULL, because there were no grouping variables left after we aggregated over race3.